
Making something modern and, more importantly, keeping it modern is a journey, a constant change. This applies to many things in life, and software is no exception. Let’s embark on this path.
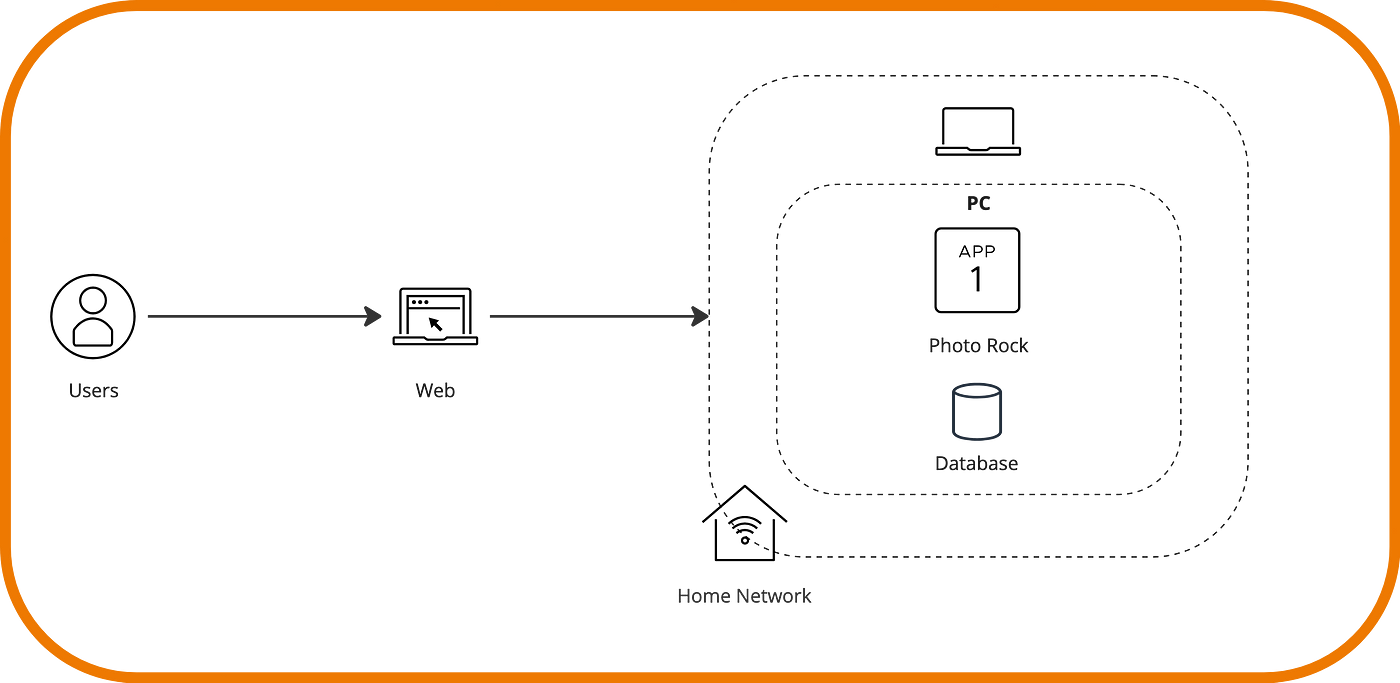
Imagine that after an overdose of listening to AC/DC, we wanted to create a website with unpublished photos of concerts in music history. We had a few free hours over the weekend (I’ll also need you to imagine this), and we launched a simple first version on our own PC. We called it ‘Photo Rock’, added a nice domain, and shared it with some friends. It would look something like this in design terms.
Our friends were thrilled with this application, and soon, word spread, and strangers started visiting it. Unfortunately, some power outages prevented everyone from accessing the site. It was time to spend a few dollars on the cloud and host our application on ‘someone else’s machine.’
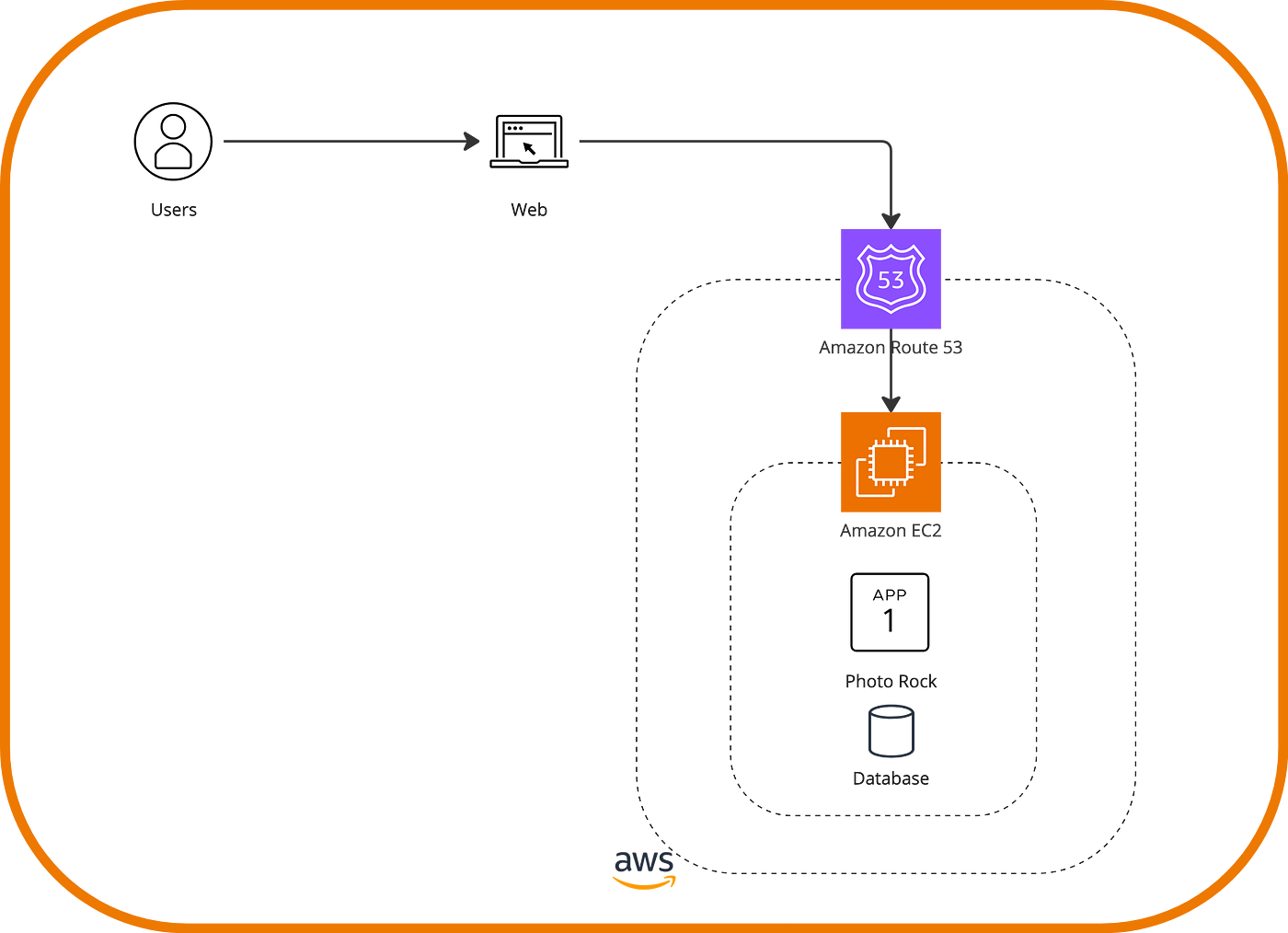
Thus, with this new setup on AWS, we introduced a first migration strategy called rehost, also known as lift-and-shift. It essentially involves moving an application to a new cloud system without modifying the original application. While this re-hosting scenario is very simple, as we merely moved our app’s content to an EC2 instance, AWS Cloud offers several services, such as AWS Application Migration Service and AWS Cloud Migration Factory Solution, which accommodate more advanced scenarios, allowing for on-premises hardware mapping if this has multiple components.
The 7 R’s
Alongside rehosting, there are seven other strategies, known as the seven R’s of migration. Let’s review each one.
Relocate
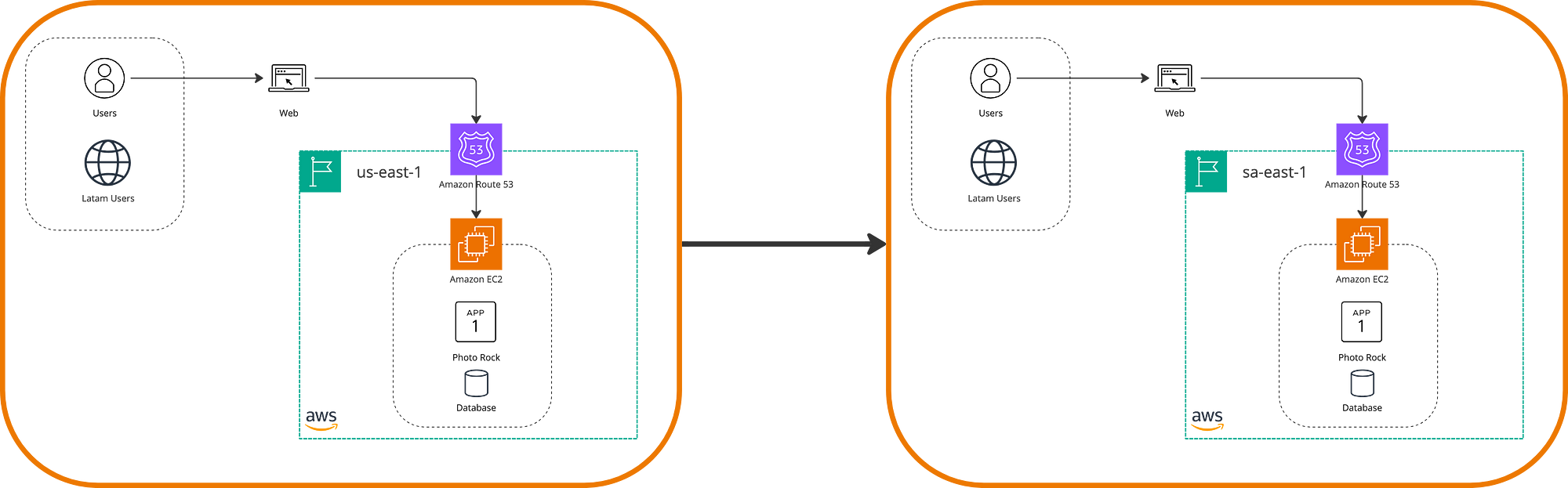
Similarly to rehosting, relocation refers to strategies for moving existing infrastructure with the difference that, in addition to not making changes to the application, no hardware purchases are made. Instead, location changes are made, such as changing accounts or regions. The reason for following this strategy can be, for example, to optimize the latency of a system without incurring multi-region expenses. Imagine, in our case, most of the users are from Latin America, but the servers are in the us-east-1 region. It makes sense to move the servers to the sa-east-1 region.
Retain
There are situations where it is better to resist change and leave everything as it is. This is the case with this type of migration or anti-migration, which, as its name suggests, involves retaining the architecture from being moved or modified from its origin, or at least part of it. Reasons such as data compliance, high risk involved, little business value, or lack of budget make retaining the architecture from changes a strategic decision.
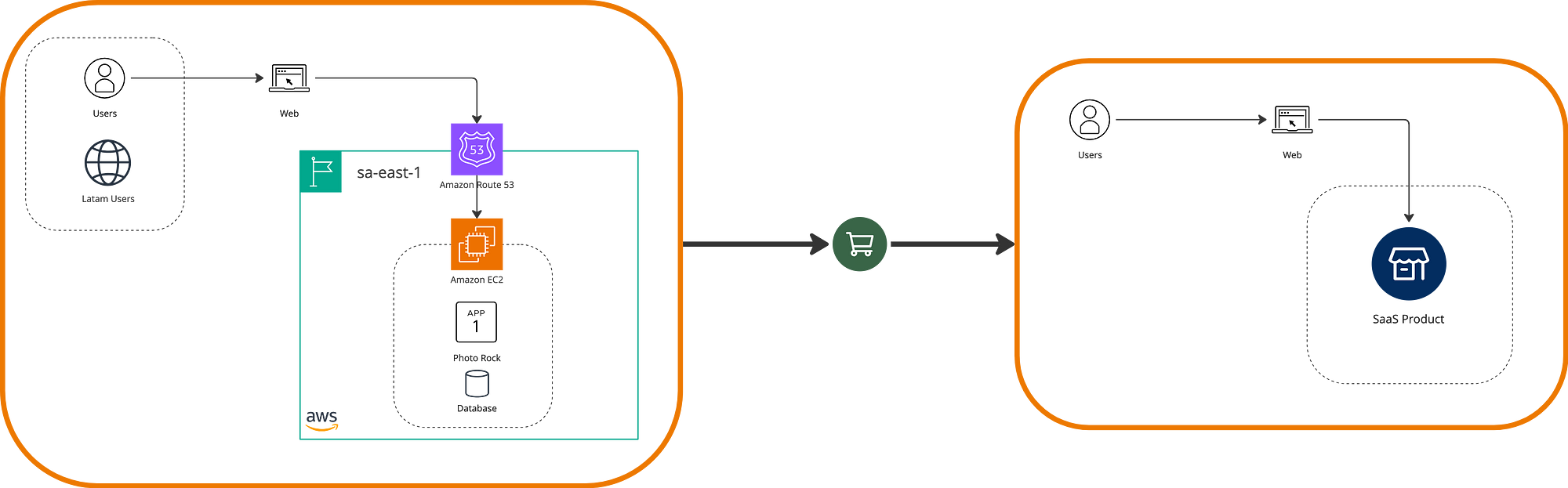
Repurchase
Let’s imagine a scenario where the Photo Rock application needs to direct investments toward marketing strategies. It would also be beneficial to develop new functionalities, but there is no technical team to handle them.
However, other external products offer exactly the functions we need, such as SaaS platforms that, through a subscription model, provide the functions of our application, being the right resource from a business perspective.
This is essentially the strategy of repurchase or drop-and-shop, where we replace our system with a different one. This can be subscription-based software or one fully acquired for use under a license, always with the aim of having a long-term benefit.
Replace & Retire
There are also times when it is better to ‘start over,’ where the cost-benefit of transforming a legacy system is less than replacing it with an entirely new one. Typically, new requirements balanced with an expectation of needs and time from the business lead to an application being dismissed or eliminated in favor of a new re-implementation.
A retirement strategy is precisely responsible for partially or completely removing elements of the system. For instance, Photo Rock might have an image editing module that users haven’t used for months, incurring server and database charges. Our architecture would be migrated to a version without these components.
There can be various reasons for retiring a system, such as mitigating risks, low performance, or business value. This decision is not always trivial, which is why there are also best practices for doing it.
Replatform
We leave for last the strategies that involve changes in the architecture, seeking an optimized version of the system at various levels. This can occur in terms of performance, costs, and availability, among other characteristics.
Replatforming refers to a migration that involves moving components to the cloud and/or between regions but also introduces changes to them. Let’s recall the previous state of Photo Rock in the cloud and now try to optimize, for example, the database so that it is managed on an independent instance. This way, we will achieve higher security in the storage and access to the data.
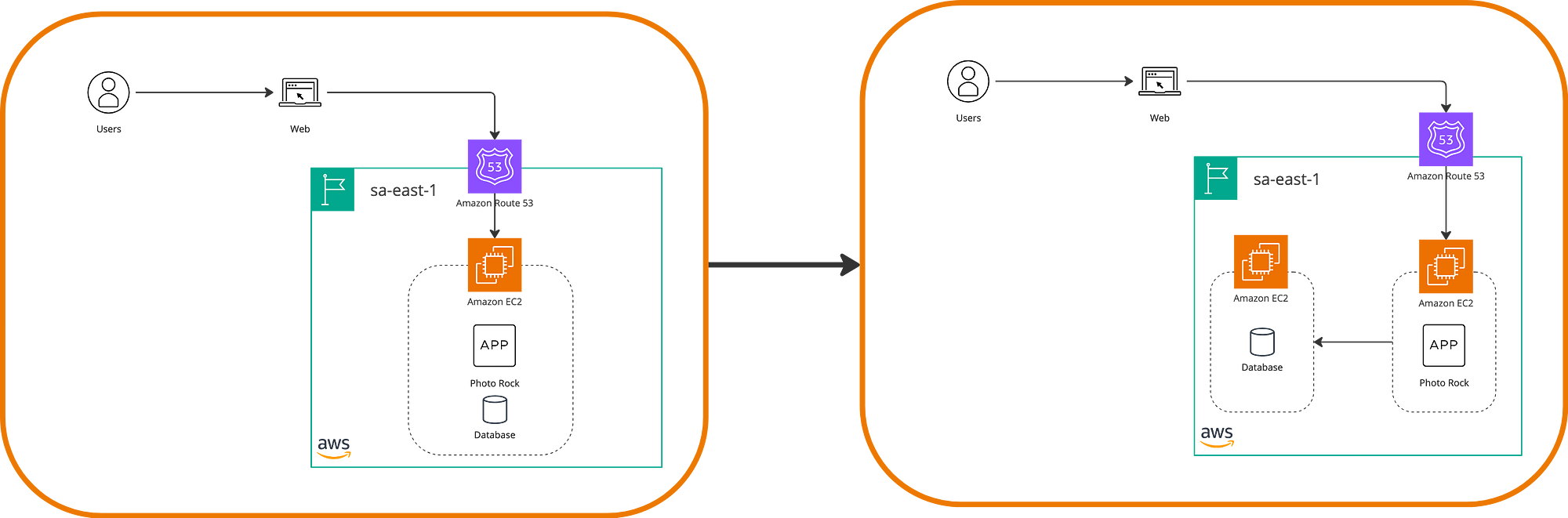
Through this strategy, one or many changes in the application can be beneficial, always depending on the business objectives and the desired architecture. Some examples of this strategy include using serverless services or migrating from Windows to Linux to save on infrastructure and licensing costs. We will delve more into the possible changes.
Refactor
Finally, we have a strategy that represents migrations with considerable re-architecture, generally to maximize the benefits of being a cloud-oriented system and achieving greater performance, availability, and scalability.
The re-architecture options are limitless, from OS changes to database schema changes and partial migrations from on-premises that require VPN communications, to name a few examples. In the case of Photo Rock, let’s consider a separation of static and dynamic content that involves changes in our application and incorporates services like S3 and CloudFront to optimize performance and availability.

Evolving Our Application
We will now focus on the Replatform and Refactor strategies, which are fundamental for system modernization due to their re-architecture and optimization characteristics.
Certainly, each ‘legacy’ application, regardless of its size, is unique in terms of design and architecture. However, there are known paths one can take to modernize their systems on AWS and help clients and businesses drive their initiatives. For this purpose, AWS has identified six possible modernization pathways.
Let’s use our example application, Photo Rock, to explore each of these aspects. These pathways are not established in a specific order, but they have different levels of difficulty and adaptation, so their implementation will largely depend on the associated business value.
Moving to Cloud-Native
AWS aims to make it easy to build applications and functionalities through decoupled components, which is somehow different from a monolithic application. To achieve this, it primarily promotes the use of microservices-based architectures and fully managed mechanisms for the main components of a system.
Starting with what we can call the entry point for many systems, the APIs, AWS offers API Gateway as a way to expose our microservices, and Lambda functions to divide the responsibilities of business logic. Additionally, DynamoDB is provided as a way to persist data, whether through a single table concept or by segregating storage into multiple tables for each microservice. With this new alternative reality, our application could look like this.
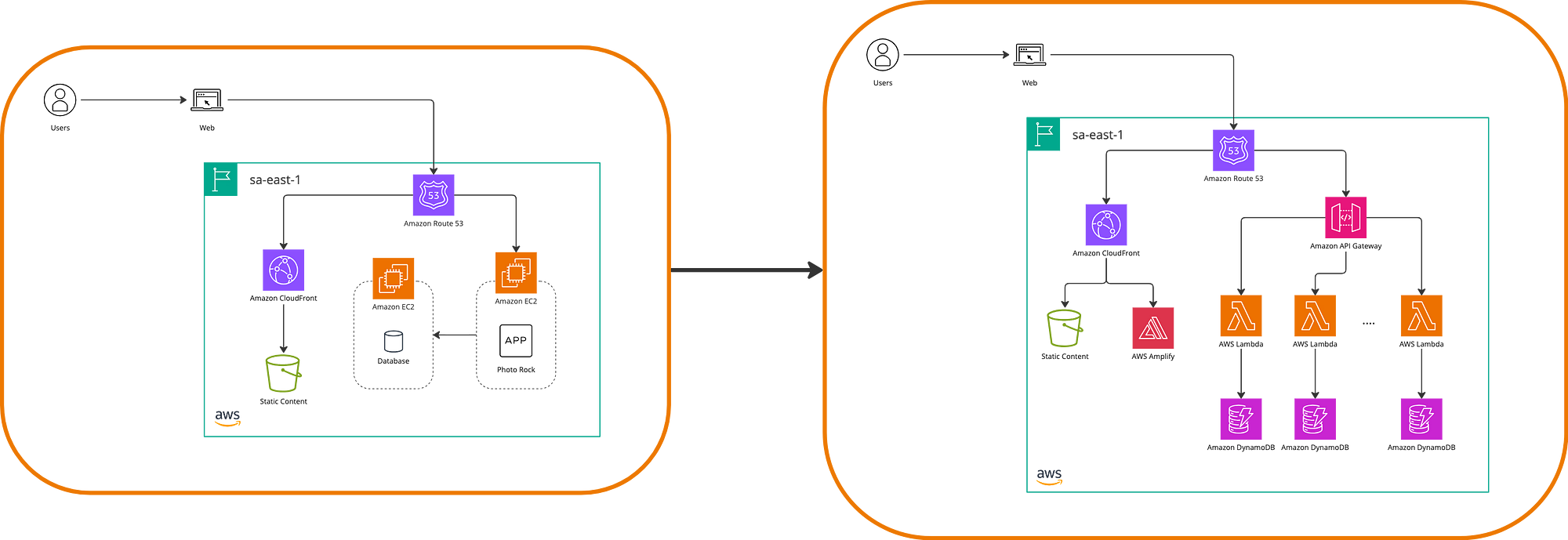
This is a rather traditional example of a 3-tier architecture, but we can also model an event-driven architecture with a similar idea of component independence. This allows us to interconnect distributed components, increasing availability and fault tolerance. Architectures of this type come in ‘2 flavors,’ as I like to think of them, depending on the system domain, and they are events or workflows. Our rock-themed website would look like this in an event-driven approach, for example, if we separate the photo uploads from the main feed and apply some image recognition.
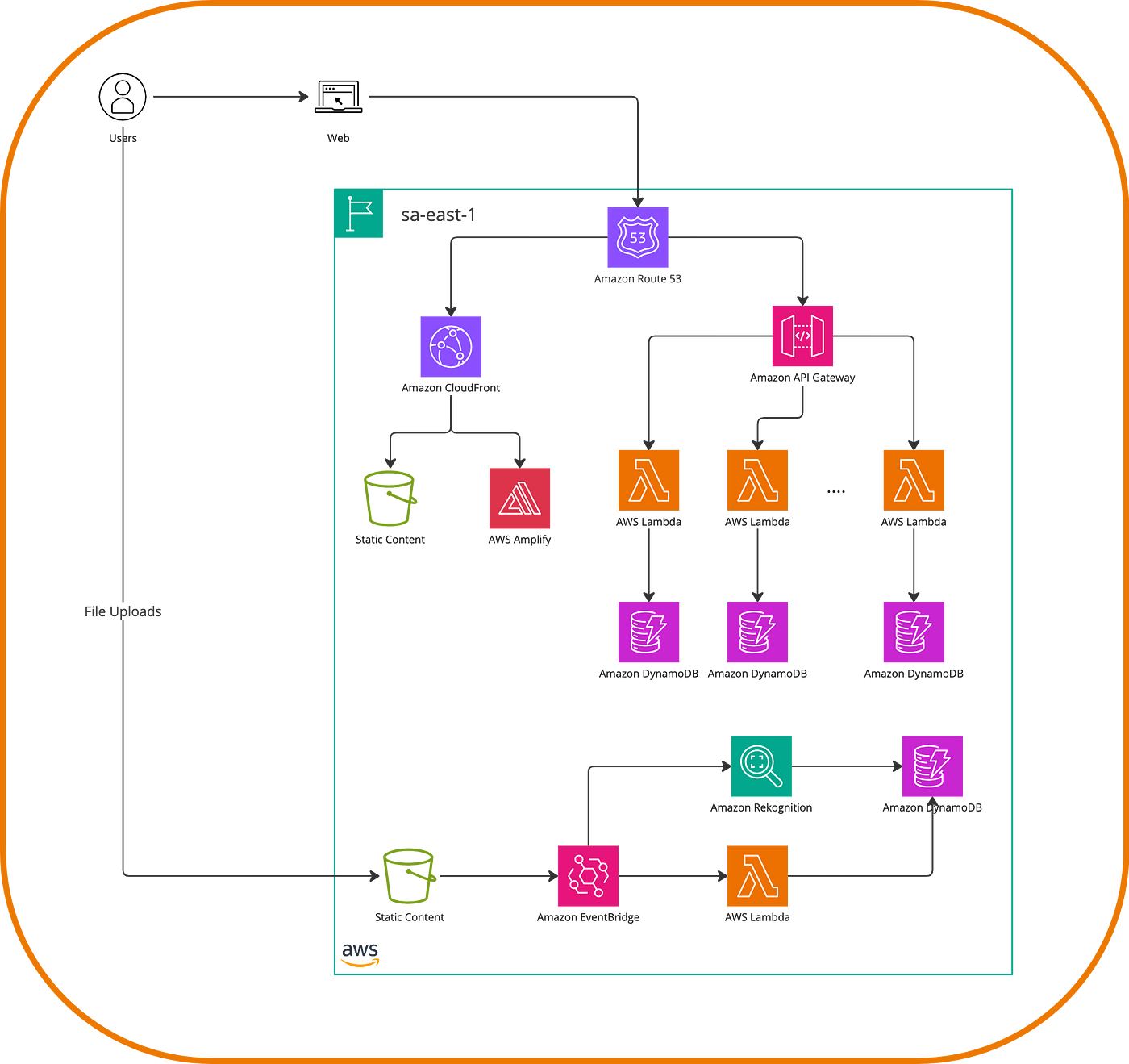
If our scenario involves additional steps and can be designed as a flow, we can use Step Functions to represent it.
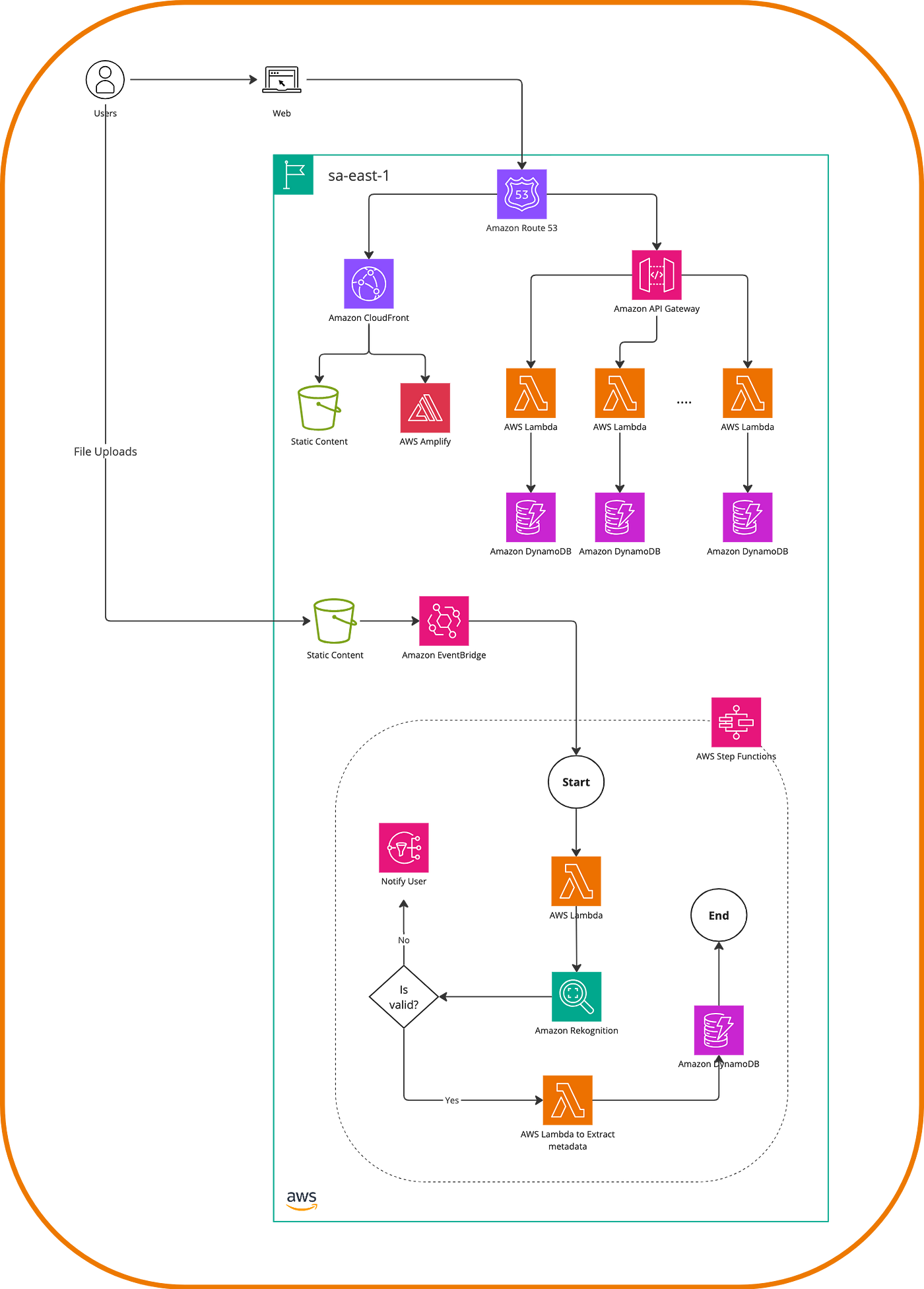
We have thus proposed a clear restructuring of our application, but I think it’s important to reason why a microservice is a better option than a monolith. Well, the truth is that it’s not always the case. It’s much easier to build a monolith than a microservices architecture. It requires fewer technical and architectural skills, which makes it a great way to start a new application. However, the reason lies in scalability and long-term maintenance; this is where a microservices architecture allows for applying best practices, working with distributed teams, and minimizing failover. Even if these microservices are composed of a series of large components, we will be heading in the right direction toward a modernized system.
When one thinks of serverless in AWS, it’s very common to associate it with AWS Lambda, but there are several surrounding services that enable highly scalable architectures. These include message queues, databases, containers, and data warehouses.
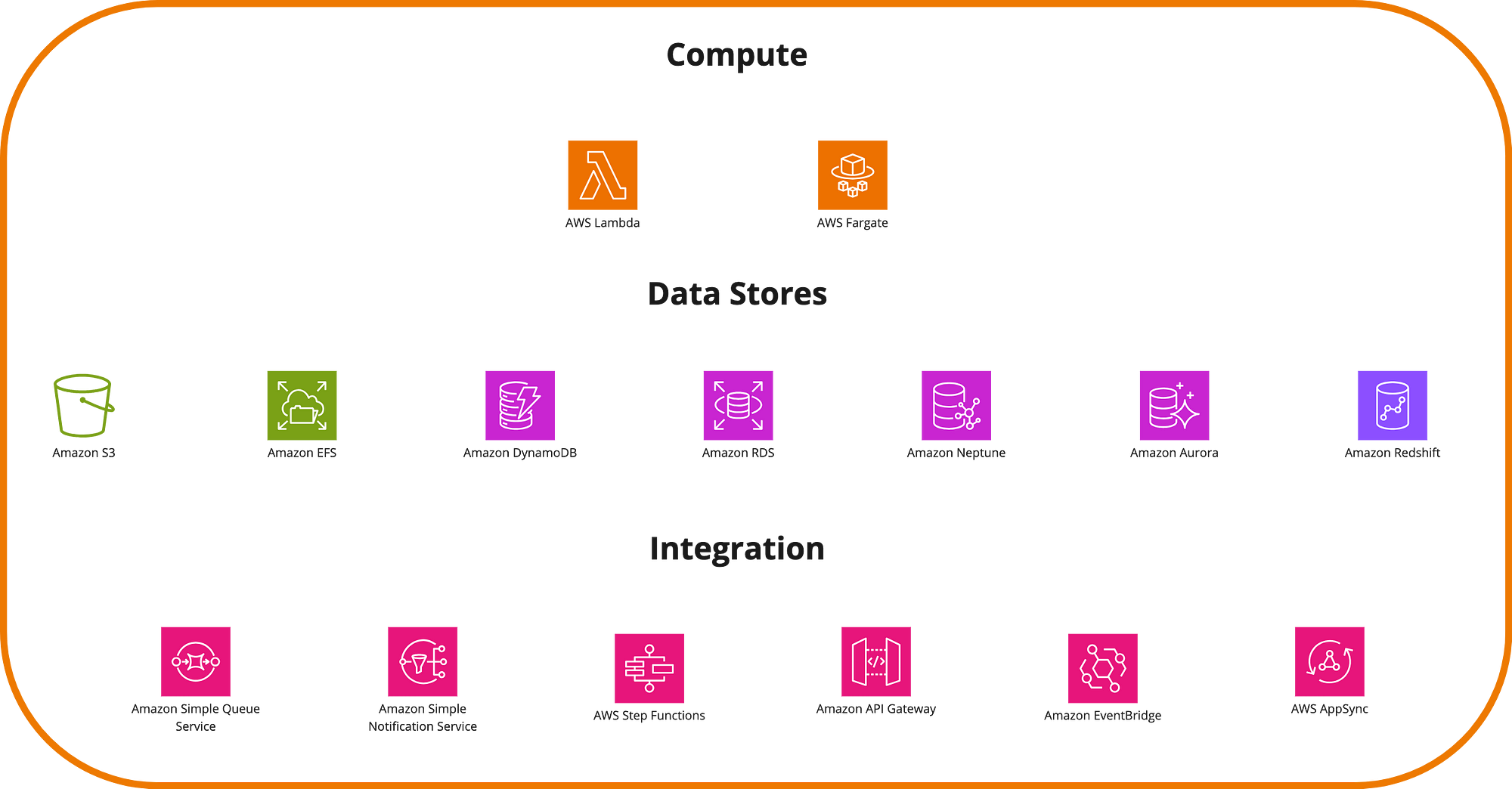
Moving to Containers
The second pathway to modernization is through the use of containers, which will optimize the consistency of our processes in both development and execution, thus reducing operational costs. They solve the big problem of ‘it works on my machine.’
Naturally, transitioning an application to use containers involves considerable effort, especially in large-scale systems. Moving to containers also doesn’t exempt us from managing our servers, even though we have a consistent format among components. This means we can make Photo Rock use Docker within EC2 instances, but we still need to ensure these containers run with the desired performance. In this operational aspect, AWS offers us two major alternatives: AWS ECS and AWS EKS.
These two services are essentially orchestrators and, as such, facilitate the management and scalability of container-based architectures. On one hand, AWS ECS is a high-level opinionated option from AWS where execution and distribution characteristics are abstracted, making it recommended for starting with container usage. It’s possible to continue using an ecosystem around it with Load Balancers, CloudWatch, CodeBuild, and a more classic stack, if we can call it that.
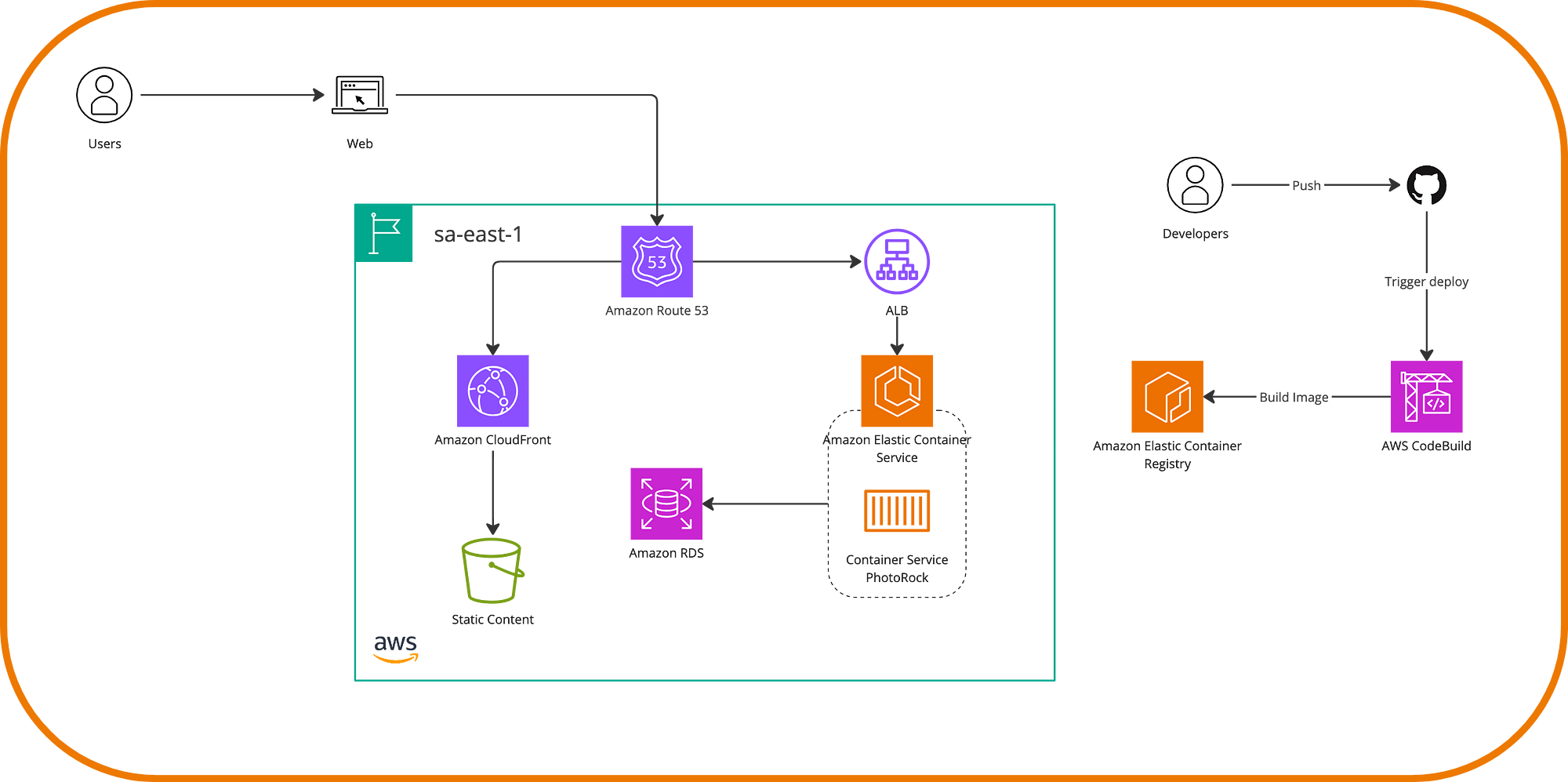
On the other hand, EKS is Amazon’s service for Kubernetes, which is the perfect choice if you have experience with this open-source service and are looking for great flexibility in node management. However, with AWS, we benefit from the resilience and security system that surrounds it.
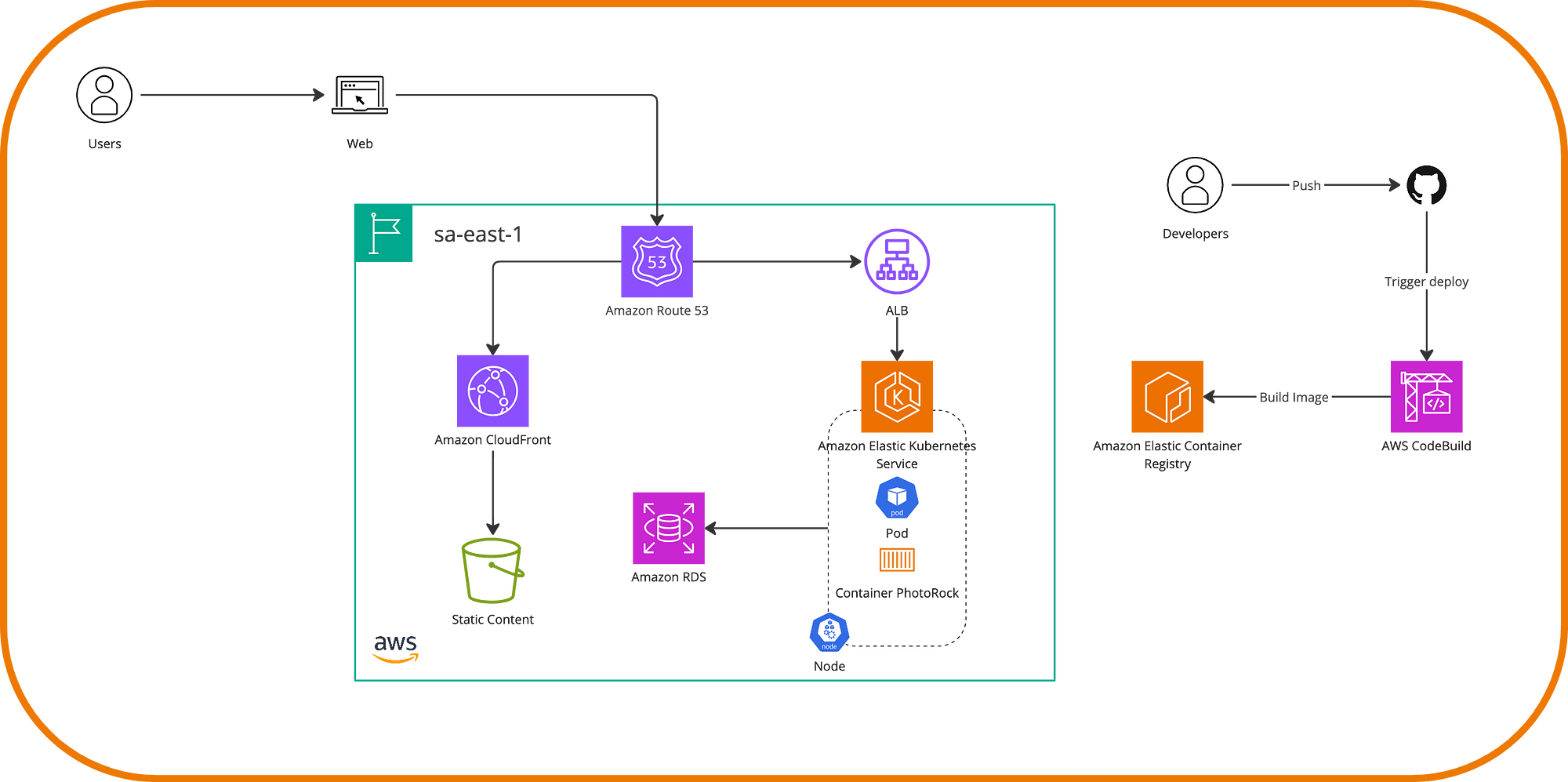
Finally, through ECR or Elastic Container Registry, AWS also offers a service for storing and distributing images, whether to transport existing images here or to integrate artifacts very effectively from CI/CD workflows with each new version of our application.
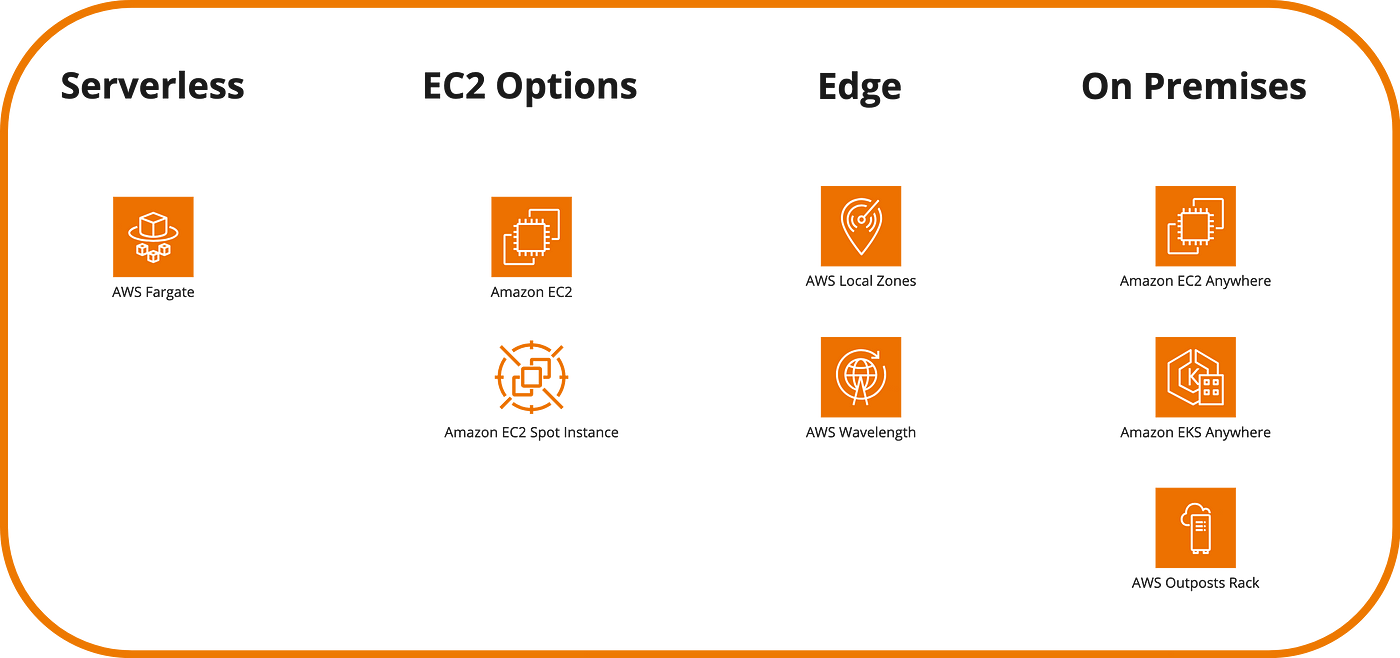
AWS ECS and EKS allow us to orchestrate containers, but we still need a layer of nodes to run them. For this purpose, there are several options that depend on costs, performance, and the level of management sought. We won’t go into the detail of each one as they deserve their own content, but it’s worth noting AWS Fargate and AWS EC2 as the two most common ecosystems, with the former managed by AWS, and EC2 as an alternative with more control over the OS and hardware features, typically using Spot Instances to optimize container management.
Moving to Fully-Managed Databases
Managing databases and all that it entails is tedious and time-consuming. This applies to managed databases both on-premises and on virtual machines, for example with EC2. We must worry about backups, availability, updates, capacity scheduling, and cluster scalability.
Moreover, we also have to consider security, both at the network level for reliable database access and data encryption compliance with certain protocols, such as HIPAA and ISO, if necessary.
It seems like a good idea to delegate this operational work and focus on designing schemas, building queries, and managing at a high level how much we want to scale our system and what type of operations we will execute on it rather than how we will achieve that from the infrastructure.
Achieving this transformation can take different paths. Perhaps the most common is migrating between relational databases, whether from on-premises, from EC2, or another cloud provider, to services like RDS or Aurora. Each of these has different characteristics but serves as a key service for AWS’s complete database management.
At Photo Rock, we carried out an example of this migration through cloud-native modernization, but AWS offers an extensive list of managed database options. Each one serves different purposes and eventually allows us not only to migrate between analogous systems but also to make schema changes. For example, if our application’s access patterns are oriented towards a social network use case, a database like AWS Neptune based on graphs might be the solution we are looking for.
How is data migration possible? Well, migrations are primarily carried out by services like AWS Database Migration Service (DMS) and AWS Schema Conversion Tool (SCT). The former allows high-level management of this operation, connecting a source and a destination, discovering and converting data, and making the migration effective. Meanwhile, as its name suggests, SCT is used for schema conversion and data warehousing information loading into Amazon Redshift. From personal experience, this can be tedious when schemas are very different, but it has a very important feature, which is continuous migration over time, not just a one-time migration. This is very convenient if you want the two systems to coexist for a period of time.
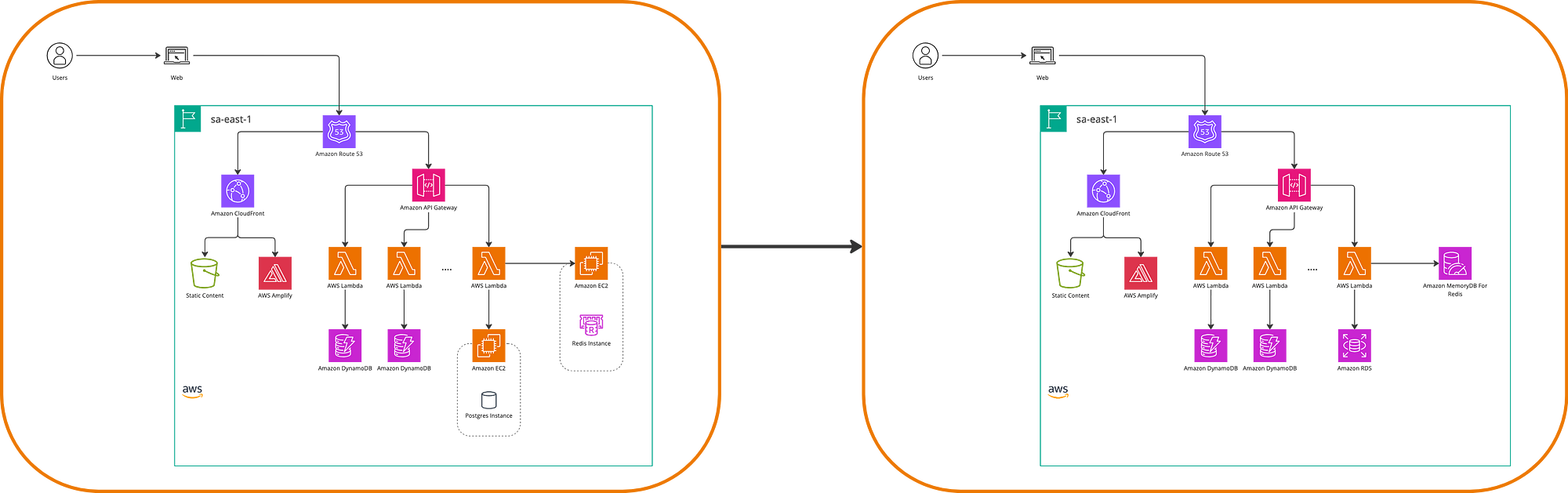
To finalize this modernization, let’s suppose that in our example application, we want to have a leaderboard with the users who contributed the most photos to the site. We decided to install Redis within EC2 initially, but a better option in this regard is to use an in-memory database such as AWS ElastiCache, which leaves a new architectural state.
Move to Open Source
In this regard, AWS seeks to offer us the ability to escape from commercial licenses. Starting at the OS level, if we have on-premises Windows machines under license, we can easily use cloud instances without much migration complexity. We can also move execution from Windows to Linux containers using the App2Container service in case our applications are developed in .NET or Java.
On the other hand, it is also possible to make a database-level transformation. If our data layer exists on SQL Server or Oracle in any of their licensed solutions, it is possible to convert them to RDS or Aurora as mentioned in the previous section.
This transformation, which will be useful if part of our solution uses commercial software, is certainly challenging in terms of planning and execution. The idea is that the return on such effort is reflected in medium—and long-term license savings.
Move to fully-managed analytics
The concept of moving to fully managed analytics introduces the idea of using Data Lakes and federations for data access—in other words, “putting data to work” to make more efficient decisions.
A modern data analytics structure consists of a set of building blocks that allow querying, monitoring, and acting on data as a whole, breaking the silo barrier. Thus, it is possible to connect multiple data sources and have different teams and apps work with and consume this information without compromising its security levels.
Imagine that at Photo Rock we want to analyze user behavior in real-time to offer personalized recommendations on which galleries to visit and thus improve the site experience. The platform collects data from various sources, including logs, mobile device usage, actions, and interactions with social networks. Then, this data can be taken in real-time by streaming services like Amazon Kinesis so that ETL processes can scan, normalize, and transform the data, using, for example, AWS Glue, and then load it into a data warehousing service like Amazon Redshift. Meanwhile, a Machine Learning team could use SageMaker to create the recommendations.
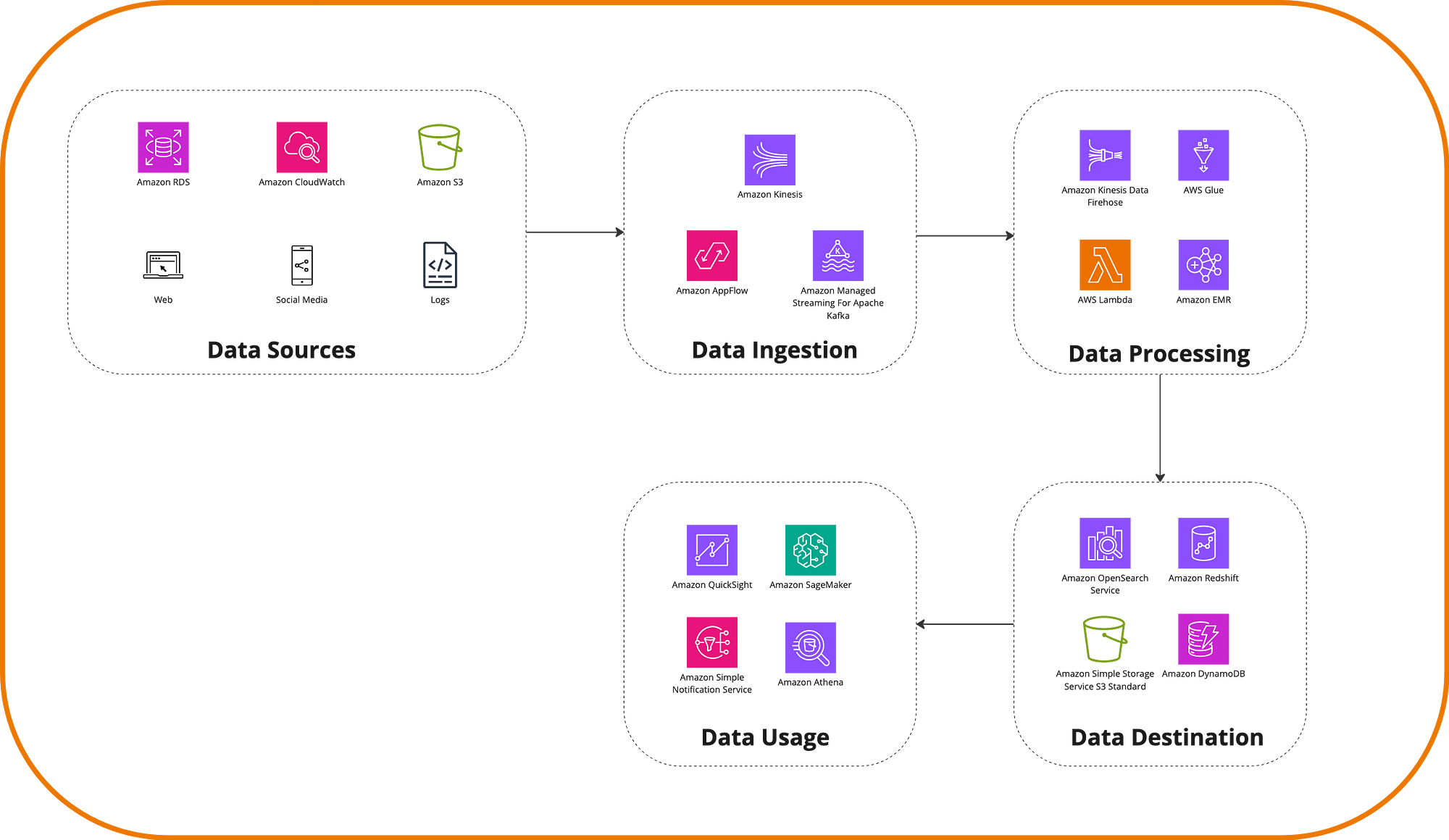
Other services associated with modernizing analytics like OpenSearch Service and Amazon EMR allow moving the effort of maintaining OpenSearch, Spark, and Hadoop for massive search and big data to the cloud. While each service deserves its own post, the reality is that different AWS services connect coherently to offer data management. Whether accessing them through purpose-built databases like Dynamo or Aurora, performing searches with OpenSearch, or using S3 as a data store with querying capabilities through AWS Athena. The goal is to use the right tool for the job.
Moving to Modern DevOps
DevOps as a concept aims to bring development and operations closer. Traditionally, these were two separate activities with different teams. Responsibilities for managing operations of a medium to large-scale system involve methodical approaches and knowledge of tools. Deploying a change to production required extensive coordination between these teams.
While DevOps does not propose merging these teams or having developers perform operations, it aims to streamline the deployment process with minimal to no errors, ideally. Through practices and tools, the focus is primarily on improving system resilience and automation.
We can simplify DevOps practices into four:
Accountability — Managing infrastructure as a whole rather than silos
Automation — Rapid changes with minimal human intervention
Awareness — Constant monitoring of the system
Autonomy — High-level governance adjustments allowing the system to operate independently
Testing is crucial to the effective use and, hence, success of DevOps. More tests lead to better quality and results, and automating their execution in each release is key to frequent releases.
AWS offers several services that cater to different stages of development, from Cloud9 and CodeCommit for development and version control, CodeBuild for task execution, and CodeDeploy for deploying changes across different services, all interconnected via CodePipeline. If I were to highlight one of these services, it would be CodeBuild as the AWS Jenkins, a fundamental component in the DevOps flow where we run tests, security checks, stress tests, and compile source code.
The following diagram illustrates how we could achieve a CI/CD flow at Photo Rock.
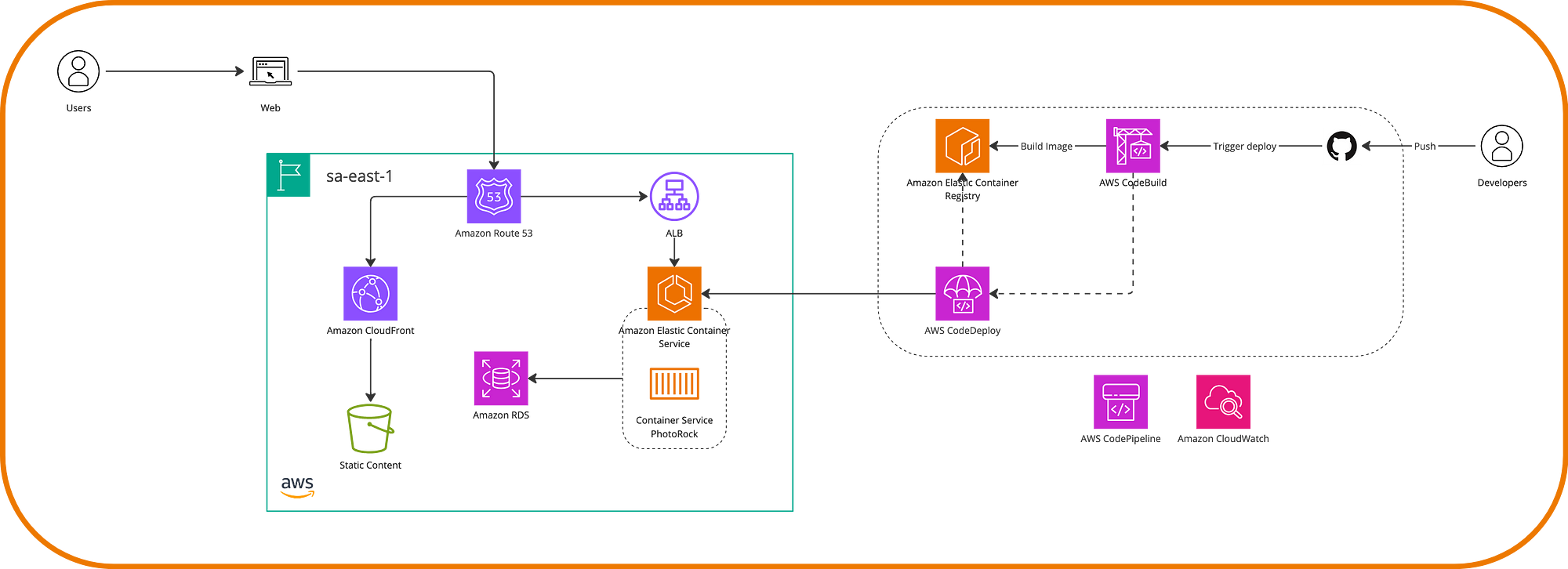
This section wouldn’t be complete without mentioning AWS CloudFormation, a service in the Infrastructure as Code (IaC) category that allows us to define the resources our system will use. It’s AWS’s counterpart to services like Terraform. While the tools and processes mentioned earlier help automate the deployment of applications and their versions, CloudFormation automates the configuration of our environment and the ability to create new environments (e.g., development, staging, production) using the same template, ensuring consistency in application deployment.
Strangler Fig
Let’s move on to the final part of this post. Consider a scenario where our Photo Rock application has grown massively as a monolith before applying any changes mentioned in the previous section. There are multiple functionalities, and more importantly, the system is in production with many users using it.
Monolithic applications are developed to provide all functionalities within a single process and with a single codebase. As a result, changes to the application require exhaustive testing to prevent regressions. Complexity increases as the system becomes enriched with more functionalities, leading to longer maintenance and innovation times. As the system grows, there’s also a cognitive aspect where boundaries of component responsibilities and understanding of the monolith can become blurred.
When a monolithic application is migrated to a microservices architecture, it can be divided into components that can scale independently. Each of these components can be developed and managed by individual teams. This transformation improves change velocity, as changes can be tested and released quickly, minimizing impact on the rest of the system.
This also suggests that moving to microservices is a good idea when the application and development team are growing or anticipated to grow. However, having a single developer manage dozens of microservices is also not advisable.
Replacing a monolith completely entails significant risk. A big bang migration, where the monolith is migrated in a single operation, introduces technical risks to the business. Additionally, while the application is being changed, adding new functionalities becomes very challenging.
One way to address this problem is by using the Strangler Fig pattern, introduced by Martin Fowler. Its name, and essentially its core idea, is based on a plant from southern Australia that envelops the branches of a tree, growing around it and absorbing its nutrients until it eventually kills it. Similarly, this pattern involves moving to microservices by gradually extracting functionalities and creating a new application around the current one. This allows users to use the new functionalities progressively. Once everything has been migrated, it becomes safe to retire the old application.
Architecture
To implement this pattern, specific functionalities are replaced with new services, one at a time. A proxy intercepts requests to our application and routes them to the legacy or new system.
Let’s assume some conditions in Photo Rock, such as having three services or APIs: User Service, Photo Service, and Cart Service. The Cart Service depends on the User Service, and we store data in a relational database. The first step would be to add a proxy that initially routes all requests to the current system. Then, if we want to add new functionalities, we do so as microservices and register them under the proxy.
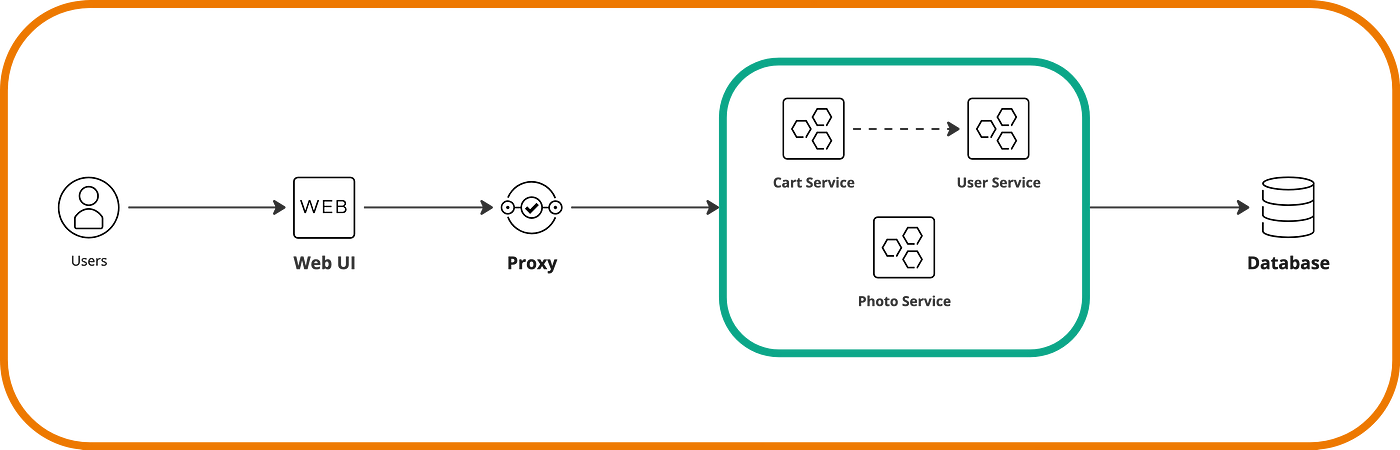
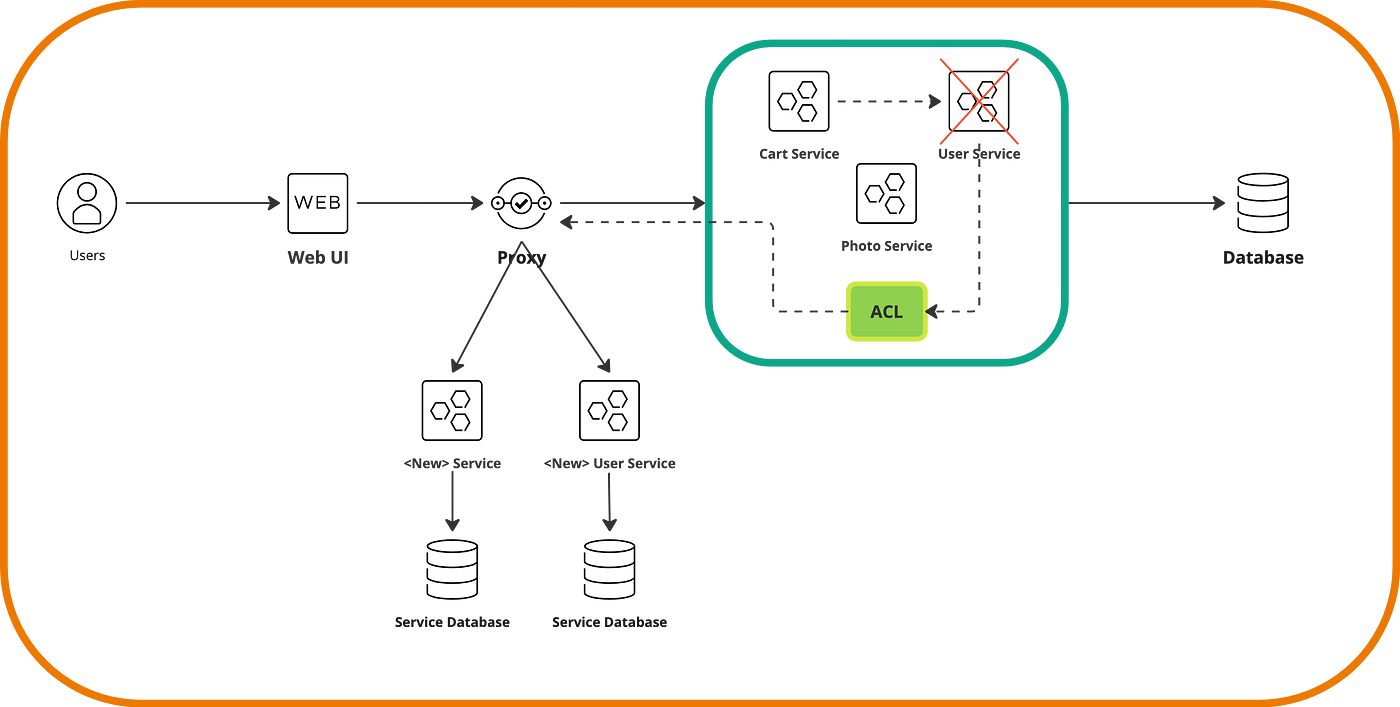
Now, let’s migrate the User Service to its own microservice. This time, it’s not enough to just register the service in the proxy because the Cart Service will continue to call this service internally. That’s why we need to implement an anti-corruption layer or ACL. This, which is nothing more than a class or code function, is introduced into the ‘old’ User Service and handles converting calls to the new microservice.
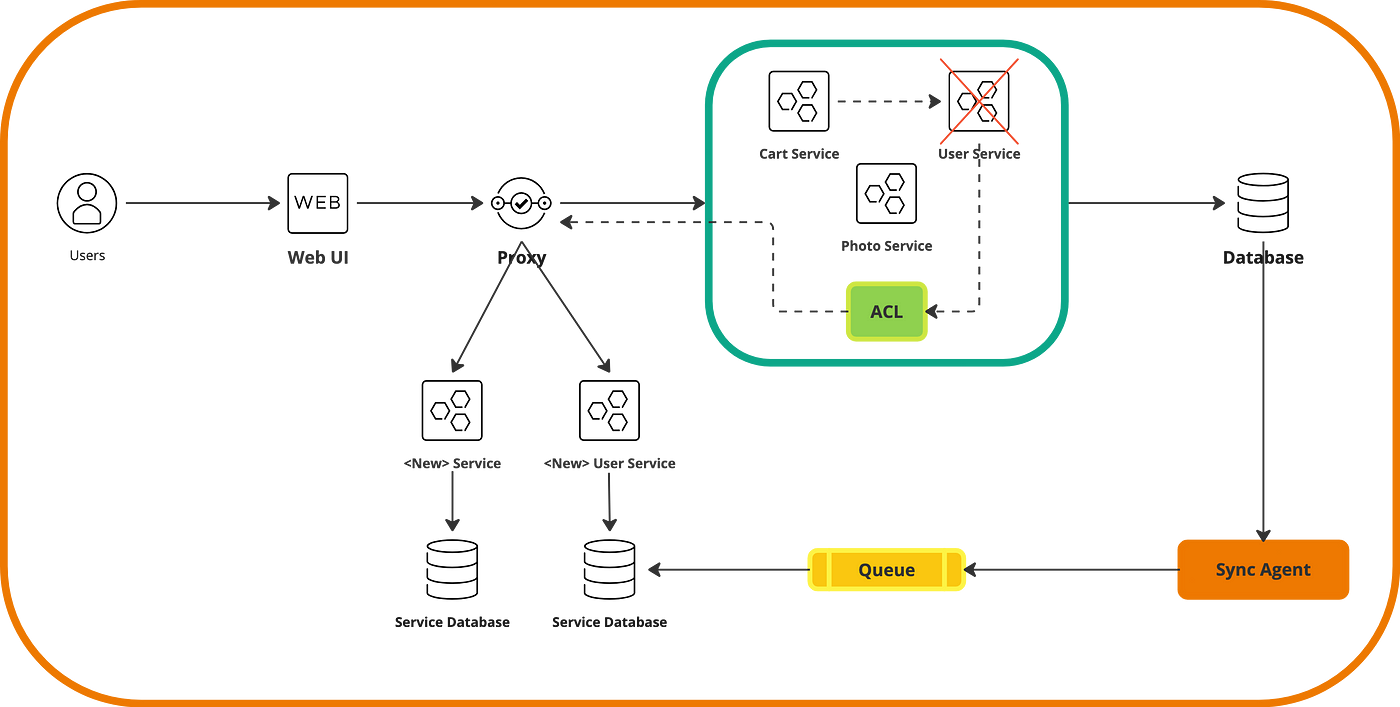
What about the data? Well, our new architecture allows the new microservices to have their own store, as shown in the previous diagram. In this scenario, we need a synchronization agent that is invoked via events whenever the original database is updated.
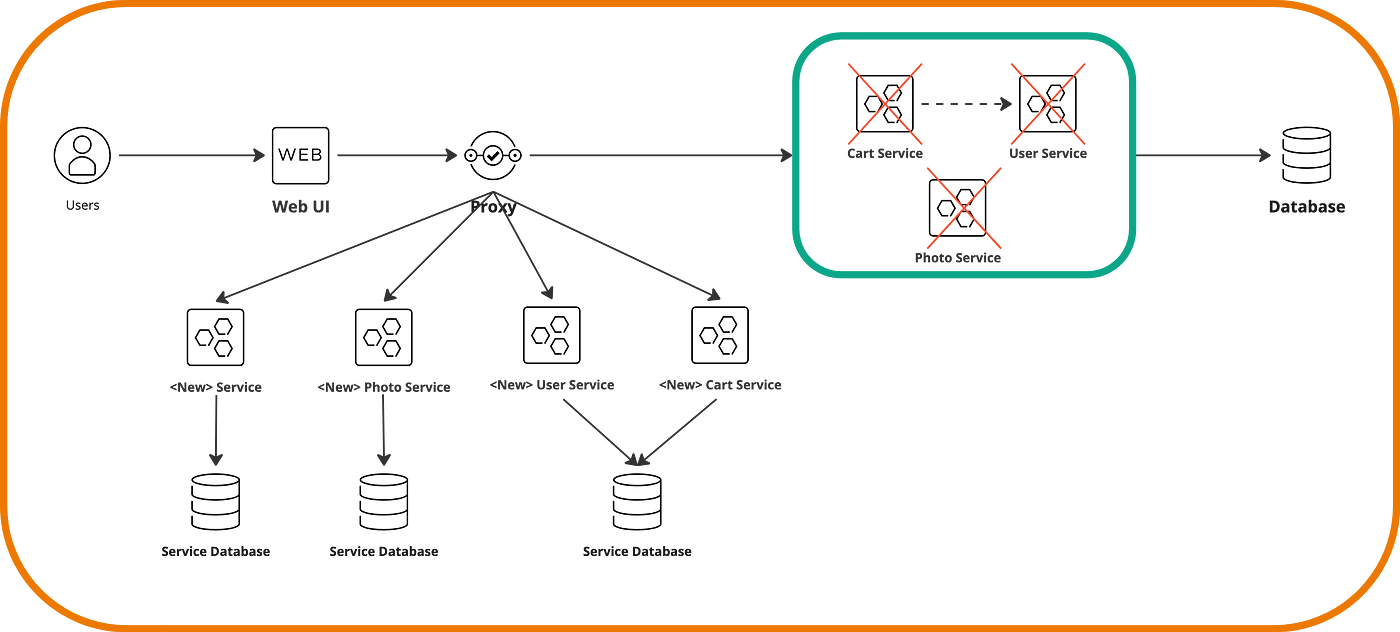
Once we migrate all services, we will have an architecture like the following, and we can retire the legacy application.
Translating to AWS
For our convenience, AWS offers a service precisely designed to implement the Strangler Fig pattern and progressive migrations. That service is AWS Migration Hub Refactor Spaces, which aims to help us create infrastructure in our account. Its value lies primarily in organizing the resources that are part of both the legacy application and the new version, as otherwise, it’s easy to lose track of what has been created, what has been migrated, and what hasn’t.
The proxy in our setup will be API Gateway, allowing routing to the monolith and avoiding being a single point of failure due to its Multi-AZ support feature. Then, services are migrated to Lambda functions, where we could eventually create tables in DynamoDB or access to ElasticCache as the independent store for each service. Refactor Spaces also allows us to register each new route and define how we want to direct the traffic of our application. The resulting architecture looks something like this.
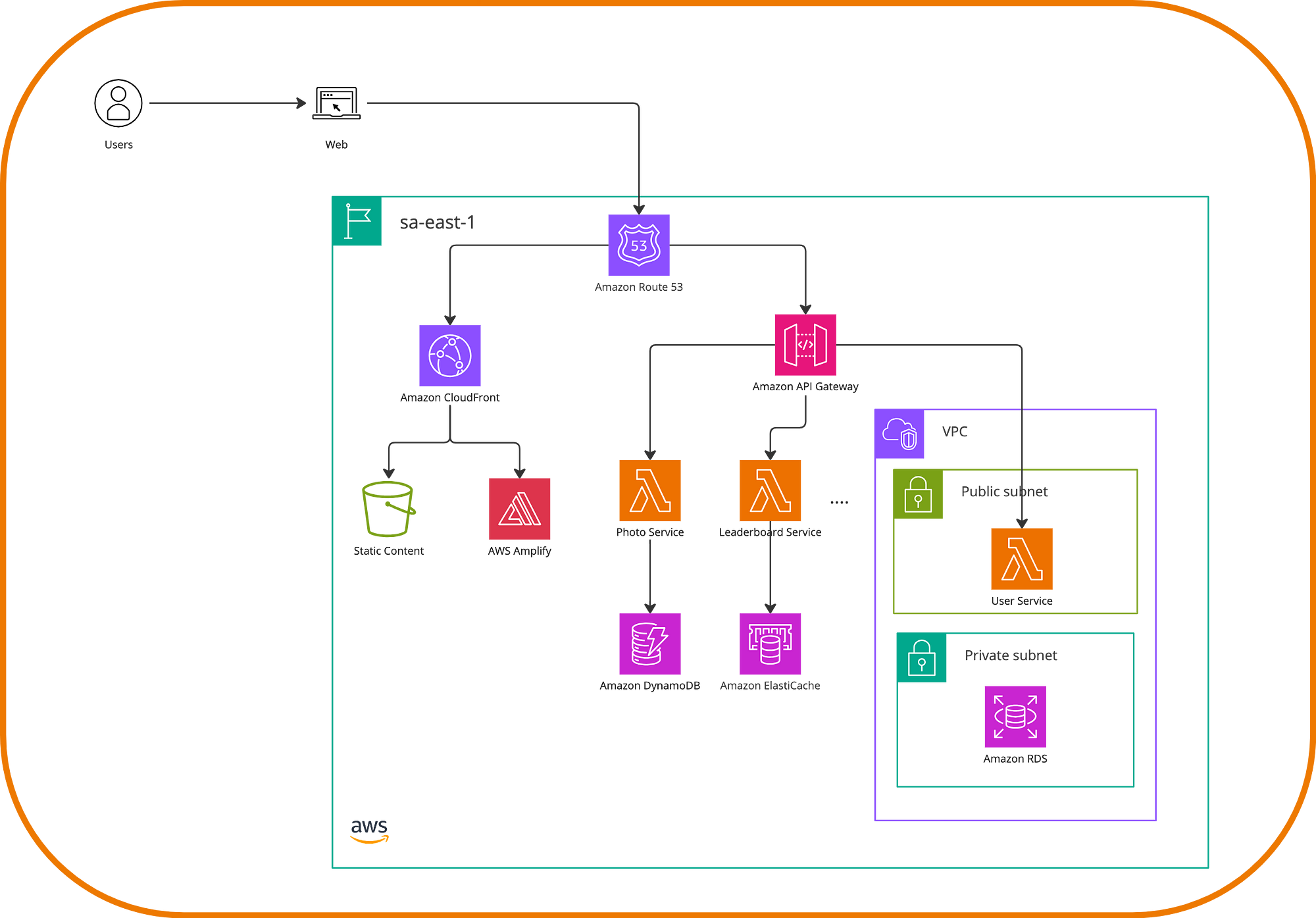
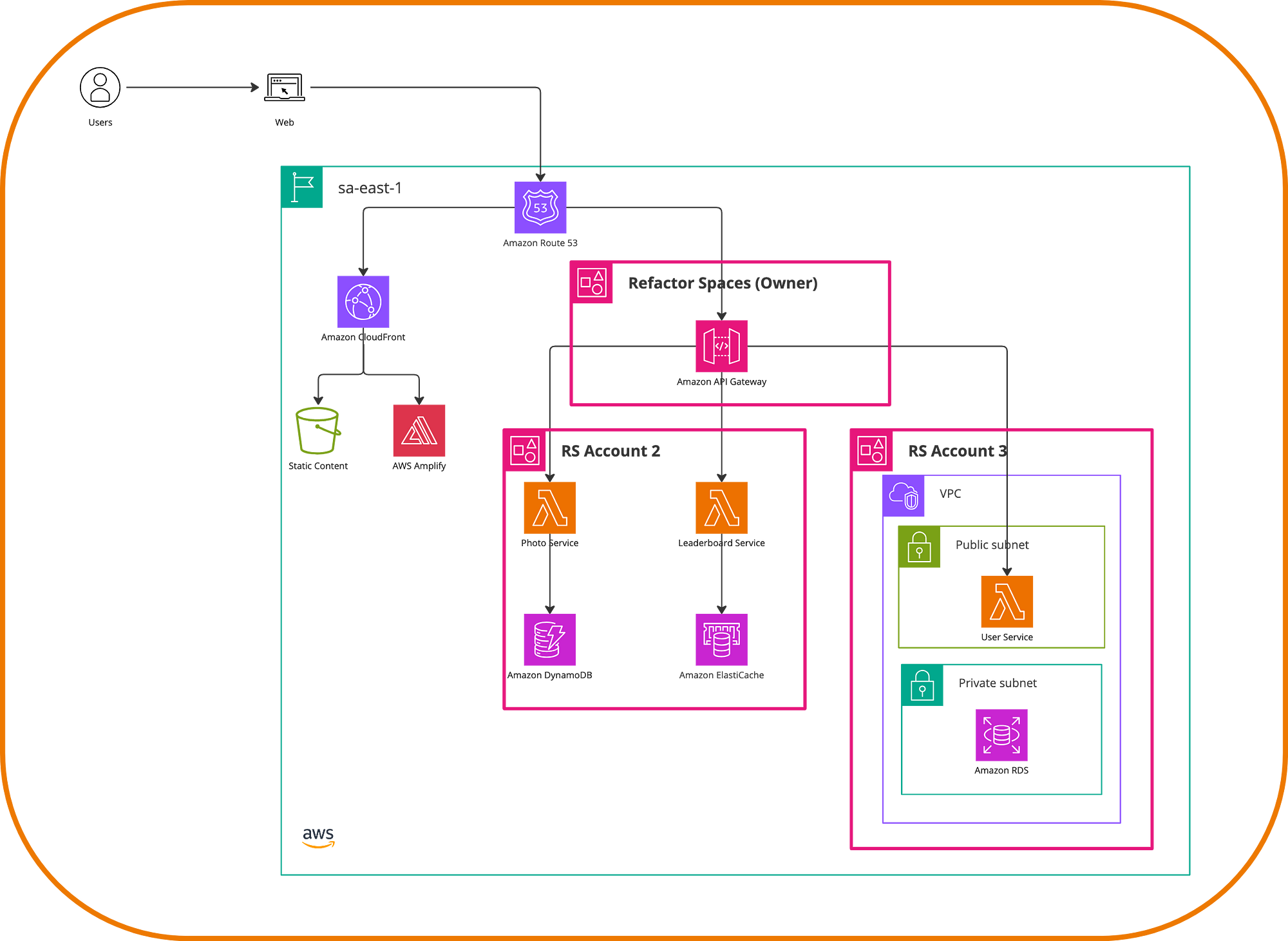
Once all services are migrated, we can further leverage Refactor Spaces to set up a multi-account version of our application. What happens there is that Refactor Spaces orchestrates API Gateway, a Network Load Balancer, and IAM Identities as part of the resources. You can seamlessly add services in one or all accounts to configure the destinations for the new microservices. One possible final architecture will look like the following.
Conclusion
Modernizing our applications to meet customer demands and take advantage of technological changes is critical to keeping an organization competitive. A key strategy to achieve this is delivering real business value by converting applications that ‘age’ over time into more modern architectures. The result of a modernization process allows us to achieve benefits such as availability, scalability, and improvements in cost-effectiveness.
While the theory is very friendly, in practice, it is very common in many organizations that the initial momentum built when starting a migration often diminishes, and things stop flowing. I believe the true potential of cloud adoption lies in continuously modernizing applications and development methodologies, thus generating convenient benefits at each stage. We must remember that today’s code will be tomorrow’s legacy application. It’s undoubtedly a long road to travel; thank you for doing it with me here.

If you’ve made it this far, thank you for reading.
You can follow me on Twitter and check other posts at ZirconTech for more tech stuff.
Will